This is Chinese version, if you have not seen the blog (in English) yet, go here: https://developmentseed.org/blog/2018/01/11/label-maker/
Label Maker is a python library to help in extracting insight from satellite imagery. Label Maker creates machine-learning-ready training data for most popular ML frameworks, including Keras, TensorFlow, and MXNet. It pulls data from OpenStreetMap and combines that with imagery sources like Mapbox or Digital Globe to create a single file for use in training machine learning algorithms.
简介:
Label Maker 是我们最近开发的开源python软件包,帮助大家更好更深刻的理解卫星影像。Label Maker 可以生成可连接到任何你喜爱的机器学习(或深度学习),比如目前最流行的谷歌TensorFlow, MXNet,用Keras来编程毫无障碍。我们的软件包从 OpenStreetMap 和Mapbox 或者Digital Globe 上面获取数据,生成训练数据集。如果有同学写出可以链接到起他卫星影像数据源上,我们也非常欢迎大家修改和提交程序到我们的GitHub repo上面。另外,如果你想学习如何做对象检测(object detection)或者影像分类(image classification)我们也给大家准备了各种例子,欢迎使用欢迎留言反馈呀。
下面是正文啦!
机器学习和深度学习算法在计算机视觉上的应用日新月异。传统的卫星影像解译非常快速也方便,比如大家可以用ERDAS,ArcGIS等做。但是这些传统的方法也有一个局限,那就是如果你的卫星影像图分辨率高一点,图片大一点了,通常这些应用软件和你的台式电脑可能就跑不动了。要快速有效的解决这些问题怎么办?我今天就来回答这个问题,我们如何借助现在的GPU和机器学习来大规模的处理和解译卫星影像。
先来小小的了解一下,现在计算机视觉里面的深度学习大概可以分为三大类:监督学习,非监督学习和强度递归学习(最后这个不知道咋翻译)。卫星图像解译传统的方法也有监督学习和非监督学习。监督学习可以理解为:你告诉帮你做图像解译的软件:河流,海洋,森林看起来是啥样子的,然后软件就根据你给的阈值去计算和分类。非监督学习就是你不告诉软件,软件根据给定的卫星影像帮你分类,比如河流和海洋,从红、绿、蓝三个波段看起来就是不一样,所以软件可以根据两类不通的波段阈值将其分开。
深度学习也可以做监督学习和非监督学习。刚才也说了,有传统软件,为啥咱们还要用深度学习呢,是因为最近大家都在哈这个吗?no,no,no。。。
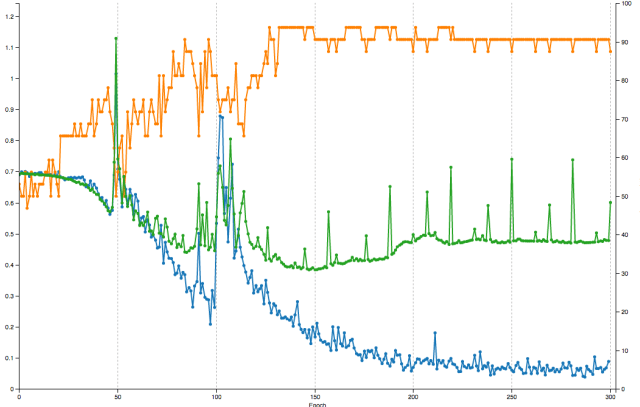
深度学习在卫星影响上出了可以通过大量使用GUP来加快计算之外,深度学习只要一次训练之后,可以利用训练好的模型权重(trained model weight)来反复训练未知的区域。你训练和学习的次数越多,时间越长,模型的表现就更好。这个链接大家可以看看我们用机器学习解译的道路网络。道路网络解译在卫星影像解译中是最难的,我先不告诉你,你自己来猜一猜下次我来公布答案。另外我们也做了很多类似的深度学习在卫星影响上的应用相关的例子,比如找房子就用到了TensorFlow对象检测,利用MXNet和亚马逊SageMaker来做的分类模型和另外一个利用Keras和亚马逊云计算机分类模型。
废话说了那么多,照着现在深度学习发展的速度,开发新的算法其事不算太难。难的是怎么准备机器学习和深度学习可以使用训练数据集。
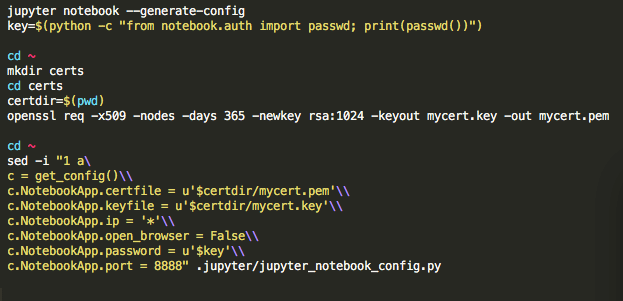
我今天隆重的来给大家介绍一下我们的pytho 软件包Label Maker。Label Maker是个开源的软件所以在github上面大家随意给我们点赞和folk,我们也鼓励大家踊跃贡献。Label Maker通过获取Mapbox的卫星影像和OpenStreetMap的矢量数据(比如道路,房子,树林)等等,打包和生成训练数据。大家可以把这个数据链接到自己最喜爱的省督学习和机器学习上面。Label Maker模型只需要五个命令行就帮你生成训练数据集了哦。
只要 pip install label_maker之后,跑这四行命令行就可以了。
label-maker download # download OpenStreetMap QA Tiles
label-maker labels # create your ground-truth labels
label-maker images # download satellite imagery tiles
label-maker package # package tiles and labels into data.npz当然我省略了两小个步骤:
比如要从Mapbox上下载卫星影像图片,你要有一个他们影像API的token,所以去注册一个Mapbox的账号吧。
然后使用上面的四个命令行之前,要生成一个配置文件(configure file),先这样的:
{
"country": "vietnam",
"bounding_box": [105.42,20.75,106.41,21.53],
"zoom": 17,
"classes": [
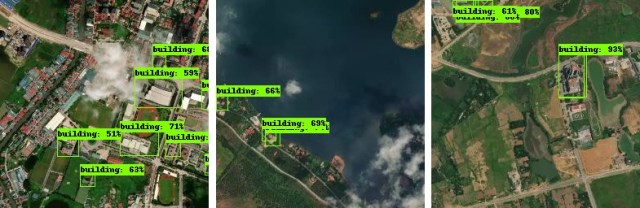
{ "name": "Buildings", "filter": ["has", "building"] }
],
"imagery": "http://a.tiles.mapbox.com/v4/mapbox.satellite/{z}/{x}/{y}.jpg?access_token=ACCESS_TOKEN",
"background_ratio": 1,
"ml_type": "classification"
}
我们的python软件包会读取配置文件里面的参数来生成你需要的训练数据集。记得在把配置文件中的ACCESS_TOKEN 替换成你mapbox上生成的token哟。
等上面四个命令行顺利跑完成之后,你就有了data.npz就可以跑你最爱的机器学习算法了。比如下面这样:
# the data, shuffled and split between train and test sets npz = np.load('data.npz') x_train = npz['x_train'] y_train = npz['y_train'] x_test = npz['x_test'] y_test = npz['y_test'] # define your model here, example usage in Keras model = Sequential() # ... model.compile(...) # train model.fit(x_train, y_train, batch_size=16, epochs=50) model.evaluate(x_test, y_test, batch_size=16)
想要了解更详细的信息不要忘了访问我们的GitHub请大家不令赐赞👍和✨吧。