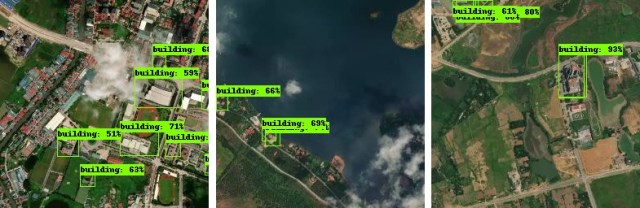
Uber will offer self-drive cars in Philly this Nov., and soon or later you will get a ride in a Uber that pops up in your doorway without a human driver. It’s so fascinating but crazy at the same time. It sounds like a science fiction, but definitely, it will be real soon. What has brought this to reality partially is machine learning, and it definitely deserves a credit.
优步打车马上就要在美国的费城像广大人民群众发布他们的无人驾驶汽车了。这个好像只有在科幻电影里面才会出现的事情,很快却要实现了,当然到大面积普及还是有一段时间的。这个无人驾驶汽车的背后是一系列神奇的算法,我们称之为‘机器学习’。
What’s machine learning? It’s a way we teach a computer to learn from thousands and millions of data records, to find patterns or rules, so it could behave/finish a task the way we want it. It is very similar to we teach babies or pets how to learn things. For example, we teach a computer in the self-drive car to remember the roads, and how to navigate in the cities for thousands of times, so it learns how to drive, so it could behave the way we want it. Let’s wait to see how the users’ reviews of Uber self-drive car this Nov.
那什么是机器学习呢?机器学习和教你的小孩和宠物学习新东西其实是无异的呢,只是机器学习里面的学生是电脑而已。就像我们说的无人驾驶汽车里面使用的电脑可以通过反复学习一个城市的路况,而再也不需要人类司机了。但是究竟这个电脑司机能比人类司机好多少倍当然就不得而知了, 所以大家就拭目以待今年11月份不同的优步用户的感受吧。
If we said, babies grow knowledge from EXPERIENCEs, and then a computer, with machine learning algorithm, learns from thousands and millions of data records. From the past (and only can be from the past because we don’t have data records from future) data records, it finds the pattern or courses that could be repeated in the future. It’s part of artificial intelligence (AI).
如果说人类的小朋友长大成熟是通过经验的积累,那么机器学习里面的机器就是通过过往的数据来学习的,请大家注意机器是只能通过过去的数据来学习的,因为我们并没有未来的数据一说。机器通过学习这些已有的数据记录找出规律和规则来指导它未来的行为。这就是机器学习,同时也是我们说的人工智能的一部分。
Machine learning algorithms are used commonly in our daily life. The recommendations from our current favorite websites, e.g. spam emails identification, your favorite movie/TV list from Amazon or Netflix, favorite songs from Spotify or Pandora. Credit card companies could spot a fraud when the credit card is used in an unusual location according to your past spending records. Several startup companies already using the algorithms to help the customers to pick up clothes according to their personal tastes. The algorithm behind the pattern sorting is Machine Learning. In these case, you would wonder how computer learns about your favors and tastes if you only use the services for several times, but don’t forget there are millions and billions of people as the data points. To a computer or an algorithm particularly, your eating, learning, tasting and other habits are the data points together with other millions of data points (users). You could be learned from your habits but also could be studied from other users in the algorithm data cloud. The accuracy of the algorithm really depends on the algorithm and the person who set the rules, though.
机器学习算法在日常生活中是非常常见的。比如大家去淘宝买东西,淘宝会有一系列你可能会喜欢的商品推荐,你去电影网站看电影它们也会通过你过往观看的影片给你推荐电影,现在的音乐网站也有推荐歌曲的列表。现在也有网站开始做根据你的个人品味配衣服这样的事情了。另外很多信用卡公司能够在第一时间通知你,你的信用卡可能被盗用。有时大家可能会觉得奇怪,为什么你只看了那么一两次网站还是会找得出你可能喜欢的东西呢?就是因为网站上所有用户其实都是一个个数据点,就像你在网站上其实也就是一个数据点一样的,网站通过学习其他成千上万个数据点,就可以把你归类了。但是大家有时候也会发现,机器也有出错的时候,而且这个几率其实也不低。这个就完全取决于机器里面的算法以及设定规则的人了。
Machine learning sounds very fancy and cutting edge but it’s not, in term of methodologies using is close to data mining and statistics, which means you could apply any statistical and mathematical methodologies you’ve learned from school. Machine learning is not about what computer languages you use to code, or it’s run on a super computer, but the essential is all about the algorithm. However, it’s very fancy in the way that the data scientists could dig out the best algorithms/ pattern from data that could assist us in a better decision on the daily basis, or you don’t even need to make a decision yourself but could just ask the Apps or your computer.
机器学习和人工智能听起来相当神秘,但是其实机器学习是比较接近数据学习和统计学的,所以你以前统计和数学课上学习过的知识都是有用的呢。机器学习的目的是找出最好的算法,而不用管你是用哪一种计算机语言写的,也不用管你的计算是否是在超级计算机上完成的。最好的算法是反映真实情况的,而且能够帮助大家在日常生活中做最好决定的算法。
These are a series of blogs that I try to write. The ultimate goal is, of course, to unlock what the popular algorithms that behind machine learning. I’ve presented a showcase in my last blog, which is the bike demand prediction of Capital Bikeshare, using multiple linear regression. This blog will be the showcase 2 of logistic regression. Even though you might think logistic regression is a kind of regressions, but it’s not. It’s a classification method; it’s used to answer YES or NO, e.g. is this patient has cancer or not; is this a bad loan or not. That’s when the false positive and false negative come in, or called them Type I error and Type II error in statistics. When you read about what it’s actually about, your math teacher might say “Type I error, and Type II error are where a positive result corresponds to rejecting the null hypothesis, and a negative result corresponds to not rejecting the null hypothesis.” And….ZZzzzz… then you fell asleep and never understood what they are.
其实我想写一系列的博客来解读机器学习这个东西,毕竟我也是统计渣而且也正在学习。主要的目的还是想通过博客写作的方式让大家(其实最主要是我自己)了解机器学习更深刻一些。我上一个博客中写到的自行车租用系统算是这一系列博客里面的第一篇吧,如果大家对机器学习感兴趣,我建议你去看一下上一篇的博客。那这个博客就算是学习案例2吧,说的是逻辑斯蒂回归模型。在过去的统计学习课上,大家可能会以为逻辑斯蒂回归模型是回归中的一种,但是其实逻辑斯蒂回归模型是一种分类方法学,是用来判断“是”或者“不是”的,比如医学中常用来判断,这个病人是不是得了癌症;银行用来判断这个贷款是不是坏账。谈到这里,那就不得不提统计学中的第一类错误和第二类错误(统计学大虾们,是这么翻译的么?!)就是false positive (故障阴性) 和 false nagative(假阳性)—什么鬼!!然后你的统计学老师就会说:第一类错误就是你的阳性结论否定你的零假设,和第二类错误是你的阴性结论否定你的零假设,然后就在怒吼一次—什!!!么!!鬼!!!!然后就直接晕厥在课堂上再也不记得老师接下来讲了什么了,是吗?!
Here is a good way to remember them.
其实应该这么记住什么是第一类错误和第二类错误。
If you are a question/make a hypothesis that ‘this person is pregnant’. Later you collected a tremendous amount of data to test your hypothesis, and here is the example what ”False Positive’ and ‘False Negative’ is:
如果你的零假设(打脸!)是“这个人怀孕了”,然后为了证明这个结论你就找了一堆数据来验证你的结论对吗?!跑了一堆逻辑斯蒂回归模型,在判断“是”或“不是”的时候,你就有了四个结论。“怀孕。是”,“没怀孕。是”,“怀孕,不是”和“没怀孕。不是”。好模型和好算法就是以上双重肯定(“怀孕。是”)和双重否定(“没怀孕。不是”)占四类情况里面的大部分,就是计算的结论是把怀孕的人归到怀孕一类,没怀孕的归到没有怀孕一类。那么一下就是第一类错误:告诉你一个男性说他怀孕了(就是上面的“没怀孕。是”没有怀孕却被认定为“是”)还有第二类错误就是:告诉一个孕妇说你没有怀孕(就是上面的“怀孕,不是”,明明人家怀孕了计算结论却认定为没怀孕)。

(Graph from https://effectsizefaq.com/category/type-i-error/ )
Note: Don’t stop here, the actual Type I error, and Type II error are a bit more complicated than this graph but hope it helps you to remember them as it does to me.
注:虽然这个图可以帮大家记住什么是统计学中的第一类错误和第二类错误,但是错误类别其实比上图要复杂那么一点点。大家想一下要是你的问题或者零假设是“这个人没有怀孕”呢?!
Showcase 2. using logistic regression to predict if your salary is gonna be more than 50K
学习案例2.用逻辑斯蒂回归模型预测个人收入是否会高于5万
Here, I use an example to tell you how it works. 下面我就给大家讲一下这个模型是怎么工作的。
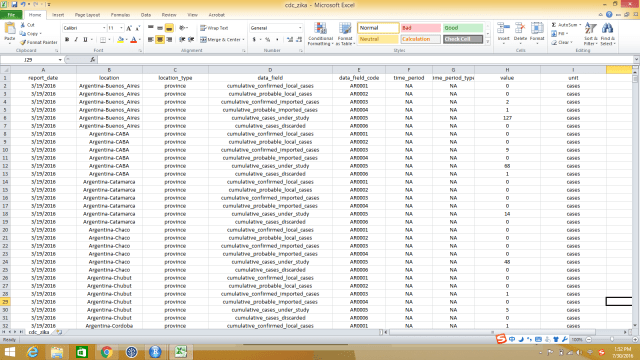
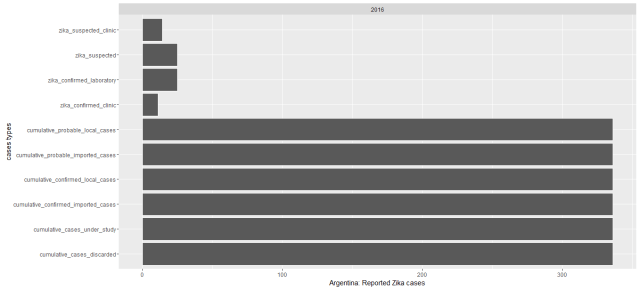
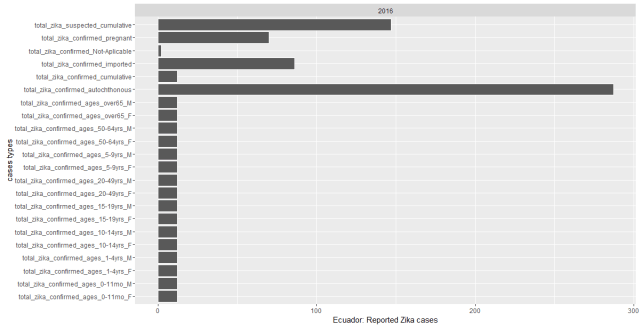
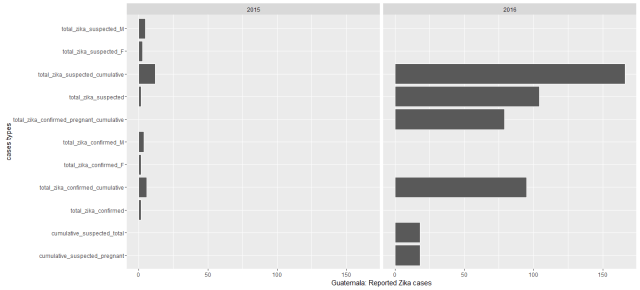
The dataset I use here was downloaded from UCI, it’s about 35,000 data records, and the dataset structure looks like the following graph. We have variables of age, type of employer, education and educational years, marital status, race, work hour per week, original country, and salary. This is just a showcase for studying logistic regression.
这个数据是从UCI下载来的,大概有3.5万条数据记录,数据格式看起来就是下图这样的。变量包括了个人年龄,雇主类型,教育情况和教育年限,婚姻状况,种族,每周工作小时数,原国籍和收入情况。这个数据只是用来学习逻辑斯蒂回归模型的,本人对结论不负责哦。

Let’s see some interesting patterns of the data, the correlation between salary categories (<50k, >50k) and education, race, sex, marital status, etc., before we go into the logistic model.
在跑逻辑斯蒂回归模型之前,让我们来看看个人的收入(薪水)类别(年薪大于五万和小于五万)和教育,种族,性别,婚姻状况都有什么联系。

People who are married tend to earn more than >50k than people who never married or currently not married.
结婚了大人可能收入大于5万的总人数会比不婚族和还没有结婚的人要高。

A lot more people earn less than 50k when they are about 25 years old, and people who are age between 40 to 50 are likely to earn more than 50k.
大部分年纪在25岁左右的人主要收入都少于5万,收入大于五万的人一般都在40岁到50岁之间。
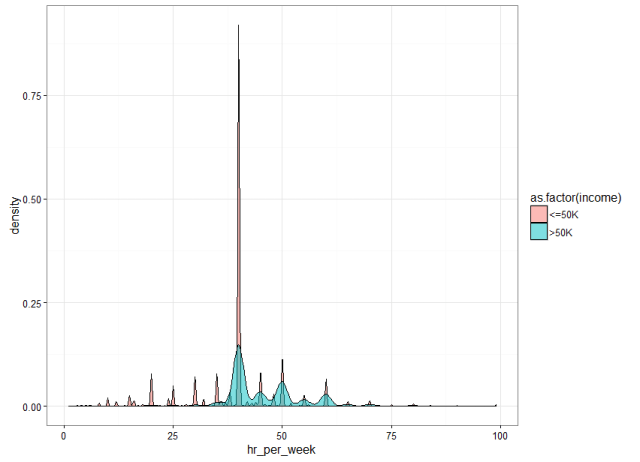
Earning more than 50k or less is not depends on longer hours you work per week.
其实不管一周工作多少个小时,收入也还是不会改变多少呢。

People who get more years of education earn a bit more doesn’t matter it’s male or female, of course, you can’t tell that if you would earn more with more education as well.
受教育多的人普遍工资都偏高,不管男性还是女性。但是也不能说明受教育年限越高就说明收入越高。
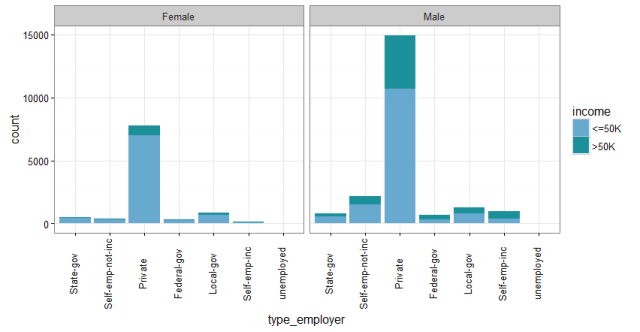
More people are employed in private sectors, and doesn’t matter where the person are employed, women are likely to be in the salary category of <50k. It means in the same type of employers; women are likely to be paid less.
数据中受雇于私人部门的人更多,而且其中男性雇员的年薪大于5万的人要比女性更多,不管他们受雇于哪一个部门。也就是说,女性在同样的工种之中可能拿到的工资比男性要低。

Before running the logistic regression, I split the dataset into 2 parts: training dataset and testing dataset. Training data takes up about 70 percent of the whole dataset. After running the model, I use the testing data to predict if my model/algorithm is good enough. This is when we will find out from the rate of Type I error and Type II error. For detail R codes I wrote you could go to my GitHub.
模型检测方法就是,在建立模型之前要把我们收集到的数据分成模型数据和检测数据。模型数据一般是整个数据的70%左右,但是这个也不一定,随你怎么定都行。一般模型运行完成之后,我们就需要把检测数据带到模型中,通过对比真实记录的结果和模型预测的结果来检测模型是否是最好的模型。我写了详细的模型代码和检测代码,原始的代码在这里.
From the model (above graph) you see that some factors (variables) have positive impacts on income, e.g. age, married, but some have negative impacts, e.g. when a person’s education is between 4th to 9th grade or preschool…Since I tried not to confuse you all with the statistical part but if you wanna understand a bit more about the statistics of the algorithm I recommend you to read this book: An Introduction to Statistical Learning. You could go to Chapter 4 particularly at this book for the logistic regression.
通过上图的模型结果大家可以看到有些变量对于个人收入的预测是有正面的影响的,比如年龄,结婚等,另外有一些又是有负面影响的,比如受教育低。这个博客写作我还是忽略了很多统计的部分。但是如果大家想了解逻辑斯蒂回归模型可以去看An Introduction to Statistical Learning 这一本书,书中讲很多R在统计学习中的应用。关于逻辑斯蒂回归模型大家直接可以跳到第四章去学习。
If we wanna know the algorithm I built was a good one, I need to test the model and these following parameters will give me an answer to it. For example, the accuracy of the model is measured by the proportion of true positive and true negative in the whole dataset.
关于我们建立的这个模型是否是个好模型那么就需要这几个参数来考量。所选模型的精确度就靠一下图中的accuracy(精确度)公式来确定了。

There are three categories of machine learning algorithms: supervised learning, unsupervised learning, and reinforcement learning. Logistic regression and linear regress have belonged to the supervised learning algorithm.
我们其实可以把机器学习的算法归为三类,分别是:监督学习,非监督学习以及加固学习。我的两个博客中提到的多元线性模型和逻辑斯蒂回归模型属于机器学习中的监督学习算法。
My best self-taught strategy is ‘learning by doing’—‘get your hand dirty’ is always the best way to get good at of somethings you wanna master, and I have so much fun learning what algorithm and statistics behind machine learning, and here are some great blogs to read too. If you are interested in learning more, you could follow my blog or twitter: @geonanayi.
我自学的宗旨是在‘动手过程中学习’, ‘get your hand dirty’永远都是最好的学习和巩固知识的最好方式。做这些案例学习真的是学习到很多背后的统计和数学方法。大家如果有时间也可以读一读这个博客,如果你想要和我一起学习“机器学习的算法”也可以加我的Twitter:@geonanayi。