The following work was done by me and Dr. Shay Strong, while I was a data engineer consultant under the supervision of Dr. Strong at OmniEarth Inc. All the work IP rights belong to OmniEarth. Dr Strong is the Chief Data Scientist at OmniEarth Inc.
以下要介绍的工作是我在OmniEarth公司做数据工程师的时候和Shay Strong博士共同完成的工作。工作的知识产权归OmniEarth公司所有,我的老板Shay Strong博士是OmniEarth公司的数据科学家团队的领头人。
A wildfire had been burning in the Great Smoky Mountains of Tennessee and raced rapidly northward toward Gatlinburg and Pigeon Forge between late Nov. and Dec. 2nd, 2016. At least 2000 buildings were damaged or destroyed across 14,000 acres of residential and recreational land, while the wildfire also claimed 14 lives and injured 134. It was the largest natural disaster in the history of Tennessee.
2016年11月到12月田纳西州的大烟山国家公园森林(Great Smoky Mountains)大火,随后火势蔓延至北部的两个地区Gatlinburg 和Pigeon Forge。据报道大火损毁2000多栋包括民宅和旅游区建筑物,损毁面积达到1万4千英亩,火灾致使14人死亡134人受伤。被认为是田纳西州历史上最大的自然灾害。
After obtaining 0.4 m resolution satellite imagery of the wildfire damage in Gatlinburg and Pigeon Forge from Digital Global, OmniEarth Inc created an artificial intelligence (AI) model that was able to assess and identify the property damage due to the wildfire. This AI model will also be able to more rapidly evaluate and identify areas of damage from natural disasters from similar issues in the future.
从Digital Global获得大约为0.4米分辨率的高分辨率遥感图像(覆盖了火灾发生的Gatlinburg 和Pigeon之后)我们建立了人工智能模型。该人工智能模型可以帮助我们快速定位和评估火宅受灾面积和损毁程度。我们希望该模型未来可帮助消防人员快速定位火灾险情和火灾受损面积。
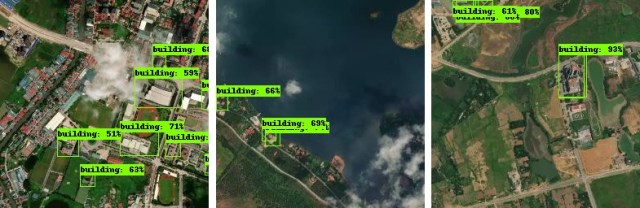
The fire damage area was identified by the model on top of the satellite images.
该地图链接是我们的人工智能模型生成的火灾受损地区热图在卫星地图上的样子:http://a.omniearth.net/wf/。

Fig 1. The final result of fire damage range in TN from our AI model. 该图是通过人工智能模型生成的火灾受灾范围图。
1. Artificial intelligence model behind the wildfire damage火灾模型背后的人工智能
With assistance from increasing cloud computing power and a better understanding of computer vision, more and more AI technology is helping us detect information from trillions of photos we produce daily.计算机图像识别和云计算能力的提升,使得我们能够借助人工智能模型获取数以万计甚至亿计的照片地图等图片中获取有用的信息。
Before diving into the AI model behind the wildfire damage, in this case, we only want to identify the differences between fire-damaged buildings and intact buildings. We have two options: (1), we could spend hours and hours browsing through the satellite images and manually separate the damaged and intact buildings or (2) develop an AI model to automatically identify the damaged area with a tolerable error. For the first option, it would easily take a geospatial technician more than 20 hours to identify the damaged area among the 50,000 acres of satellite imagery. The second option poses a more viable and sustainable solution in that the AI model could automatically identify the damaged area/buildings less than 1 hour over the same area. This is accomplished by image classification in AI, using convolutional neural networks (CNN) specifically, because CNN works better than other neural network algorithms for object detection and recognition from images.
在深入了解人工智能如何工作之前,在解决火灾受灾面积和受损程度这个问题上,其实我们要回答的问题只有一个那就是如何在图像上区分被烧毁的房屋和没有被烧毁的房屋之间的区别。要回答这个问题,我们可以做:(1)花很长的时间手动从卫星影像中用人眼分辨受损房屋的位置;(2)建一个人工智能模型来快速定位受损房屋的位置。现在我们通常的选择是第一种,但是在解决田纳西那么多房屋损毁的卫星影像上,我们至少需要一个熟悉地理信息系统和遥感图像的技术人员连续工作至少20个小时以上才能覆盖火灾发生地区覆盖大约5万英亩大小的遥感图像。相反,如果使用人工智能模型,对于同样大小区域范围的计算,模型运行到出结果只需要少于1小时的时间。这个人工智能模型具体来说用的是卷积神经网络算法,属于图像分类和图像识别范畴。

Fig 2. Our AI model workflow. 我们的人工智能模型框架。
Artificial intelligence/neural networks are a family of machine learning models that are inspired by biological neurons of our human brain. First conceived in the 1960s, but the first breakthrough was Geoffrey Hinton’s work published in the mid-2000s. While our human eyes work like a camera seeing the ‘picture,’ our brain will process it and be able to construct the objects we see through the shape, color, and texture of the objects. The information of “seeing” and “recognition” is passing through our biological neurons from our eyes to our brain. The AI model we created works in a similar way. The imagery is passed through the artificial neural network, and objects that have been taught to the neural network are identified with certain accuracy. In this case, we taught the network to learn the difference between burnt and not-burnt structures in Gatlinburg and Pigeon Forge, TN.
2. How did we build the AI model
We broke down the wildfire damage mapping process into four parts (Fig 1). First, we obtained the 0.4m resolution satellite images from Digital Globe (https://www.digitalglobe.com/). We created a training and a testing dataset of 300 small images chips (as shown in Fig 3, A and B) that contained both burnt and intact buildings, 2/3 of which go to train the AI model, CNN model in this case, and 1/3 of them are for test the model. Ideally, the more training data used to represent the burnt and non-burnt structures are ideal for training the network to understand all the variations and orientations of a burnt building. The sample set of 300 is on the statistically small side, but useful for testing capability and evaluating preliminary performance.
 |
 |
| Fig 3(A). A burnt building |
Fig3(B). Intact buildings |
Our AI model was a CNN model that built upon Theano (GPU backend) (http://deeplearning.net/software/theano/). Theano was created by the Machine Learning group at the University of Montreal, led by Yoshua Bengio, who is one of the pioneers behind artificial neural networks. Theano is a Python library that lets you define and evaluate mathematical expressions with vectors and matrices. As a human, you can imagine our daily decision-making is based on the matrices of perceived information as well, e.g. which car you want to buy. The AI model helps us to identify which image pixels and patterns are fundamentally different between burnt and intact buildings, similar to how people give a different weight or score to the car brand, model, and color they want to buy. Computers are great at calculating matrices, and Theano brings it to next level because it calculates multiple matrices in parallel, and so speeds up the whole calculation tremendously. Theano has no particular neural network built-in, so we use Keras on top of Theano. Keras allows us to build an AI model with a minimalist design on training layers of a neural network and run it more efficiently.
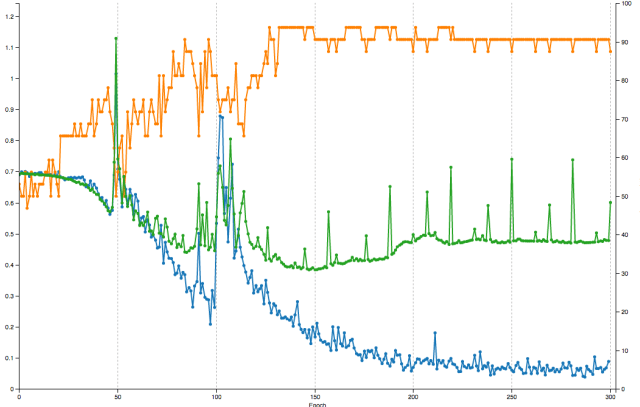
Our AI model was run on AWS EC2 with a g2.2xlarge instance type. We set the learning rate (lr) to 0.01.. A smaller learning rate will force the network to learn more slowly but may also lead to optimal classification convergence, especially in cluttered scenes where a large amount of object confusion can occur. In the end, our AI model with came out with 97% of accuracy, less than 0.3 loss over three runs within a minute, and it took less than 20 minutes to run on our 3.2G satellite images.
The model result was exported and visualized using QGIS (http://www.qgis.org/en/site/). QGIS is an open source geographic information system that allows you to create, edit, visualize, analyze and publish geospatial information and maps. The map inspection was also done through comparing our fire damage results to the briefing map produced by Wildfire Today (https://inciweb.nwcg.gov/incident/article/5113/34885/) and Incident Information System (https://inciweb.nwcg.gov/incident/article/5113/34885/).
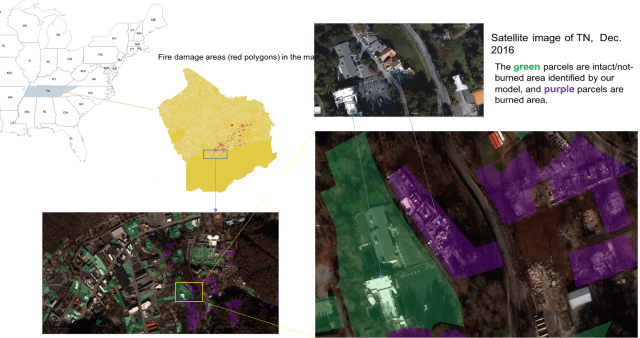
Fig 4. (A). using OmniEarth parcel level burnt and intact buildings layout on top of the imagery.

Fig 4 (B). The burnt impact (red color) on top of the Great Smoky Mountains from late Nov. to early Dec 2016.
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. A lot of currently available classification approaches are not suitable to handle high-resolution imagery data with inherent high variability in geometry and collection times. However, OmniEarth is a startup company that is passionate about the business of science and scaling quantifiable solutions to meet the world’s growing need for actionable information.
Contact OmniEarth for more information:
For more detailed information, please contact Dr. Zhuangfang Yi, email: geospatialanalystyi@gmail.com; twitter: geonanayi.
or
Dr. Shay Strong, email: shay.strong@omniearthinc.com; twitter: shaybstrong.