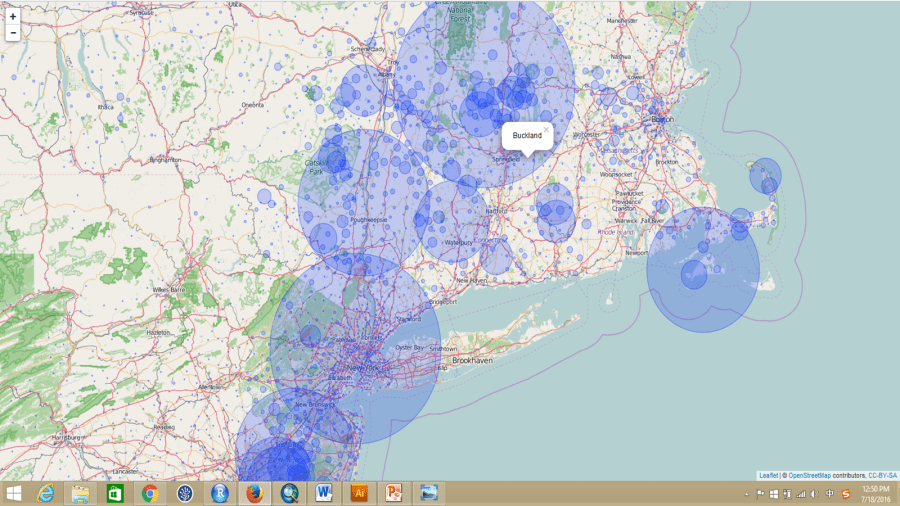
Please go ahead and play with the full-screen map here.
This map Application is developed to support the Guidelines for Sustainable Development of Natural Rubber, which led by China Chamber of Commerce of Metals, Minerals & Chemicals Importers & Exporters with supports from World Agroforestry Centre, East and Center Asia Office (ICRAF). Asia produces >90% of global natural rubber primarily in monoculture for highest yield in limited growing areas. Rubber is largely harvested by smallholders in remote, undeveloped areas with limited access to markets, imposing substantial labor and opportunity costs. Typically, rubber plantations are introduced in high productivity areas, pushed onto marginal lands by industrial crops and uses and become marginally profitable for various reasons.
这个应用地图集的开发是为了支持由中国五矿化工进出口商会和世界农用林业中心等部门联合编制的《可持续天然橡胶指南》。亚洲天然橡胶的产量占全球的90%,且主要是在有限的种植地区内,通过单一的种植,达到最高的产量。橡胶主要是由小农户在偏远的、欠发达的、市场有限的地区通过利用大量的劳动力和机会成本获得的。一般来说,橡胶只应该种植在高产量的地区,但已经被工业化的发展推到了在边缘土地上种植,并因种种原因已经边缘到无利可图。

Fig. 1. Rubber plantations in tropical Asia. It brings good fortune for millions of smallholder rubber farmers, but it also causes negative ecological and environmental damages.
图1:亚洲热带橡胶种植园。它给数以万计的小橡胶农民带来收入,但它也造成了负面的生态和环境的破坏。
The online map tool is developed for smallholder rubber farmers, foreign and domestic natural rubber investors as well as different level of governments.
The online map tool entitled “Sustainable and Responsible Rubber Cultivation and Investment in Asia”, and it includes two main sections: “Rubber Profits and Biodiversity Conservation” and “Risks, SocioEconomic Factors, and Historical Rubber Price”.
该在线地图工具开发是为了小胶农、国内外天然橡胶投资者以及政府层面的政府使用。
这个标题为“亚洲可持续和负责任的天然橡胶种植和投资”的在线地图工具,包括两个主要部分:“橡胶利润和生物多样性保护”和“风险、社会经济因素和历史橡胶价格”。
The main user interface looks like the graph (Fig 2). There are 4 theme graphs and maps.
主用户界面看起来像图表(见图2)。有4个主题图和地图。
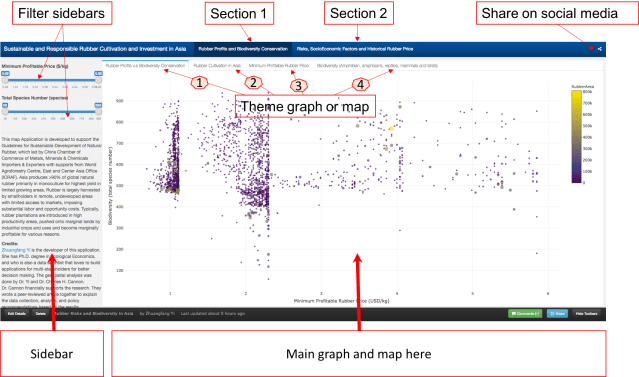
Fig. 2. The main user interface of the online map tool.
图2:在线地图工具的主要用户界面。包括上图可见的“简介”,“第一部分”,“第二部分”,和“社交媒体分享”。
. Section 1 第一部分内容
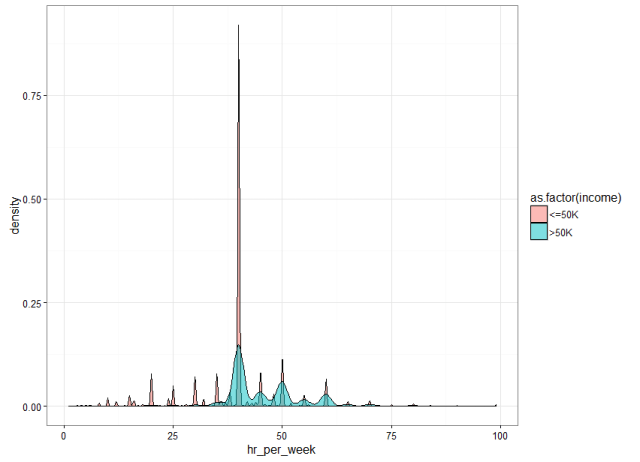
This graph tells the correlation between “Minimum Profitable Rubber (USD/kg)” (the x-axis of the graph, and “Biodiversity (total species number)” in 2736 county that planted natural rubber trees in eight countries in tropical Asia. There are 4312 counties in total, and in this map tool, we only present county that has the natural rubber cultivated.
这张图显示了亚洲热带地区八个国家种植天然橡胶树的2736个县的最低橡胶成本(美元/千克)(图的X轴)和生物多样性(总种数)之间的关系。共有4312个县,在这个地图工具中,我们只提供了有天然橡胶种植的2736县相关的内容。

Fig. 3. How to read and use the data from the first graph. Each dot/circle represents a county, the color, and size of it indicates the area of natural rubber are planted. When you move your mouse closer to the dot, you will see “(2.34, 552) 400000 ha @ Xishuangbanna, China”, 2.34 is the minimum profitable rubber price (USD/kg), 552 is the total wildlife species including amphibians, reptiles, mammals, and birds. “400000 ha” is the total area of planted natural rubber plantation from satellite images between 2010 and 2013. “@ Xishuangbanna, China” is the geolocation of the county.
图3:如何阅读和使用第一个图中的数据。每个圆点/圆代表一个县,其颜色和大小表示天然橡胶种植面积。当你移动你的鼠标时,比如你会看到“(2.34,552)400000公顷的“西双版纳、中国”,2.34是最低盈利(成本)橡胶价格(美元/公斤),552是总的野生物种,包括两栖动物、爬行动物、哺乳动物和鸟类。“400000公顷”是2010~2013年间卫星影像种植天然橡胶种植园的总面积。“西双版纳、中国”是本县的地理位置。
Don’t be shy, please go ahead and play with the full-screen map here. The minimum profitable rubber price is the market price for national standard dry rubber products that would help you to start makes profits. For example, if the market price of natural rubber is 2.0 USD/kg in the county your rubber plantation located, but your minimum profitable rubber price is 2.5 USD/kg means you will lose money by just producing rubber products. However, if your minimum profitable rubber price is 1.5 USD/kg means you will still make about 0.5 USD/kg profit from your plantation.
请不要拘谨,可以在这里浏览全屏地图。最低橡胶成本换算成国家标准的干橡胶产品的市场价格,这将有助于你理解您所属橡胶园的盈利起始点。例如,如果你所在的橡胶种植区的天然橡胶市场价格是2美元/公斤,但你的最低成本橡胶价格是2.5美元/公斤,意味着你生产橡胶产品就会亏本。然而,如果你的最低成本的橡胶价格是1.5美元/公斤意味着你的种植园仍然会赚约0.5美元/公斤的利润。
The county that has a lower minimum profitable price for natural rubber is generally going to make better rubber profit in the global natural rubber market. However, as scientists behind this research, we hope that when you rush to invest and plant rubber in a certain county, please also think about other risks, e.g. biodiversity loss, topographic, tropical storm, frost as well as drought risks. They are going to be shown later in this demonstration.
那些天然橡胶经营平均成本最低的县,在全球天然橡胶市场上将获得较好的橡胶利润。然而,作为这项研究背后的科学家,我们希望,当你在某个县匆忙投资成本较低的县市种植橡胶时,也要考虑其他风险,例如生物多样性丧失、地形、热带风暴、霜冻以及干旱风险。这些将被显示在这个演示之后。

Fig. 4. The first map is the “Rubber Cultivation Area”, which shows the each county that has rubber trees from low to high in colors from yellow to red. The second map “Minimum Profitable Rubber Price”(USD/kg), again the higher the minimum profitable price is the fewer rubber profits that farmers and investors are going to receive. The third map is ” Biodiversity (Amphibians, Reptiles, Mammals, and Birds)”, data was aggregated from IUCN-Redlist and BirdLife International.
图4:第一张地图是“橡胶种植区”,它显示了每个县的橡胶树种植数量从低到高的颜色,即从黄色到红色。第二张图“最低成本”(美元/千克),橡胶的平均成本越高,橡胶园的经营者就会获得更少的利润。第三地图是“生物多样性(两栖动物、爬行动物、哺乳动物和鸟类)”,数据来自世界自然保护联盟红色名录IUCN-Redlist和国际鸟盟聚集BirdLife International。
. Section 2 第二部分
We also demonstrated different types of risks that investors and smallholder farmers would face when they invest and plant rubber trees. Rubber tree doesn’t produce rubber latex before 7 years old, and the tree owners won’t make any profit until the tree is around 10 years old in general. In this section, we presented “Topographic Risk”, ” Tropical Storm”, “Drought Risk”, and “Frost Risk”.
我们还展示了投资者和小农投资种植橡胶树时会面临的不同风险类型。橡胶树种植前7年在橡胶树不生产任何胶乳的情况下是没有任何盈利的,甚至橡胶园的经营者一般在橡胶树种下10年之前都不会获利。该部分中,我们提出了“地形风险”、“热带风暴”、“干旱风险”和“霜冻风险”。

Fig. 5. Section 2 ” Risks, SocioEconomic Factors and Historical Rubber Price” has seven different theme maps and interactive graphs. They are “Topographic Risk”, ” Tropical Storm”, “Drought Risk”, and “Frost Risk”, “Average Natural Rubber Yield (kg/ha.year)”, “Minimum Wage for the 8 Countries (USD/day)”, and ” 10 years Rubber price”.
图5:第2节“风险、社会经济因素和橡胶价格历史”有七种不同的主题地图和互动图表。它们是“地形风险”、“热带风暴”、“干旱风险”、“霜冻风险”、“平均天然橡胶产量(千克/公顷)”、“8个国家的最低工资(美元/天)”和“10年橡胶价格”。
If you are interested in how the risk theme maps were produced, Dr. Antje Ahrends and her other coauthors have a peer-reviewed article published in Global Environmental Change in 2015. “Average Natural Rubber Yield (kg/ha.year)” and “Minimum Wage for the 8 Countries (USD/day)” dataset was obtained from International Labour Organization (ILO, 2014) and FAO.” 10 years Rubber price” was scraped from IndexMudi Natural Rubber Price.
这个互动地图集中展示的所有内容都是有科学依据的。如果你想知道风险专题地图是如何编制的,Antje Ahrends博士和其他合作者有一篇同行评审的论文,发表在2015年的国际期刊《全球环境变化》。“平均天然橡胶产量(公斤/公顷/年)”和“8国家最低工资(元/天)”的数据来自国际劳工组织(ILO,2014年)和联合国粮农组织。“10年橡胶价格”来自于天然橡胶的价格indexmudi。
Dr. Chuck Cannon and I are wrapping up a peer-reviewed journal article to explain the data collection, analysis, and policy recommendations based on the results, and we will share the link to the article once it’s available. Dr. Xu Jianchu and Su Yufang have shaped and provided guidance to shape the online map tool development. We could not gather the datasets and put insights to see how we could cultivate, manage, and invest in natural rubber responsibly without other scientists and researchers study and contribute to field for years. We appreciated Wildlife Conservation Society, many other NGOs and national department of rubber research in Thailand and Cambodia for their supports during our field investigation in 2015 and 2016.
Chuck Cannon博士和我正在撰写一篇同行评议的科研期刊文章,用来解释该地图集生成的数据收集、分析等等,还包括了政策建议。文章一旦发表,我们会和您分享文章的链接。许建初博士和苏宇芳博士为在线地图集的开发提供了非常宝贵的意见和建议。我们无法收集数据集、并在没有其他科学家和研究人员的研究和贡献的情况下深入了解如何才能负责任地种植、管理和投资天然橡胶。我们感谢野生动物保护协会和许多其他非政府组织,以及泰国和柬埔寨国家橡胶研究院在2015和2016年的实地调查中给予的支持。
We have two country reports for natural rubber in Thailand, and natural rubber and land conflict in Cambodia, a report support this online map tool is finalizing and we will share the link soon when it’s ready.
我们有两份关于泰国天然橡胶和柬埔寨天然橡胶和土地利用冲突的国家报告,一份支持这一在线地图工具的报告正在定稿,我们将很快分享这一链接。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Technical sides 技术层面
The research and analysis were done in R, and you could find my code here.
The visualization is purely coded in R too, isn’t R is such an awesome language? You could see my code for the visualization here.
研究和分析是利用R完成的,您可以在这里找到我的代码。
可视化地图也是在R中利用纯编码编写的,难道R不是一个很棒的语言吗?你可以在这里看到我的可视化代码。
To render geojson format of multi-polygon, you should use:
library(rmapshaper) county_json_simplified <- ms_simplify(<your geojson file>)
My original geojson for 4000+ county weights about 100M but this code have help to reduce it to 5M, and it renders much faster on Rpubs.com.
我原来的GeoJSON 4000 +县级文件大小约100兆,但是这行代码有效的使文件降低到5兆。
I learnt a lot from this blog on manipulating geojson with R and another blog on using flexdashboard in R for visualization. Having an open source and general support from R users are great.