Project idea
Photovoltaic (PV) solar panels, which convert solar energy into electricity, are one of the most attractive options for the homeowners. Studies have shown that by 2015, there are about 4.8million homeowners had installed solar panels in the United States of America. Meanwhile, the solar energy market continues growing rapidly. Indeed, the estimated cost and potential saving of solar is the most concerned question. However, there is a tremendous commercial potential for the solar energy business, and visualizing the long term tendency of the market is vital for the solar energy companies’ survival in the market . The visualization process could be realized by examining the following aspects:
- Who has installed PV panels, and what are the characteristics of the household, e.g. what’s the age, household income, education level, current utility rate, race, home location, current PV resource, existing incentive and tax credits for those that have installed PV panels?
- What does the pattern of solar panel installation looks like across the nation, and at what rate? Which household is the most likely to install solar panels in the future?
The expected primary output from this proposal is a web map application . It will contain two major functions. The first is the cost and returned benefit for the households according to their home geolocation. The second is interactive maps for the companies of the geolocations of their future customers and the growth trends.
Initial outputs
The cost and payback period for the PV solar installation: Why not go solar!

Incentive programs and tax credits bring down the cost of solar panel installation. This is the average costs for each state.

Going solar would save homeowners’ spending on the electricity bill.

Payback years vary from state to state, depending on incentives and costs. High cost does not necessarily mean a longer payback period because it also depends on the state’s current electricity rate and state subsidy/incentive schemes. The higher the current electricity rate, the sooner you would recoup the costs of solar panel installation. The higher the incentives from the state, the sooner you will recoup the installation cost.
How many PV panels have been installed and where?
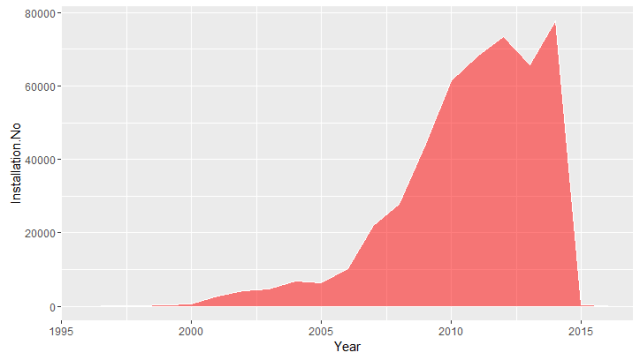
The number of solar panels installed in the states that have been registered on NREL’s Open PV Project. There were about 500,000 installations I was able to collect from the Open PV Project. It’s zip-code-based data, so I’ve been able to merge it to the “zip code” package on R. My R codes file is added here at my GitHub project.
Other statistical facts : American homeowners who installed solar panels generally has $25,301.5higher household income compare to the national household income. Their home located in places that have higher electricity rate, about 4 cents/kW greater than the national average, and they are also having higher solar energy resource, about 1.42 kW/m2 higher than the national average.
Two interactive maps were produced in RStudio with “leaflet”
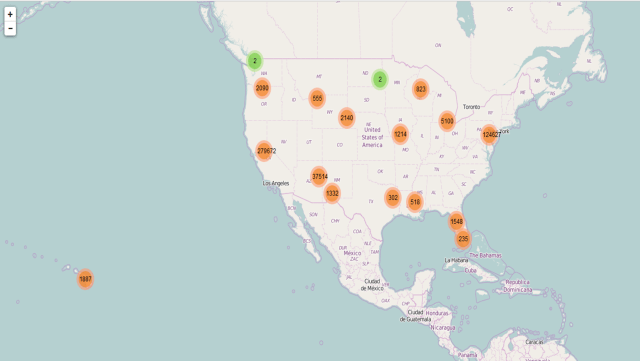
An overview of the solar panel installation in the United States.

Residents on the West Coast have installed about 32,000 solar panels from the data registered on the Open PV Project, and most of them were installed by residents in California. When zoomed in closely, one could easily browse through the details of the installation locations around San Francisco.
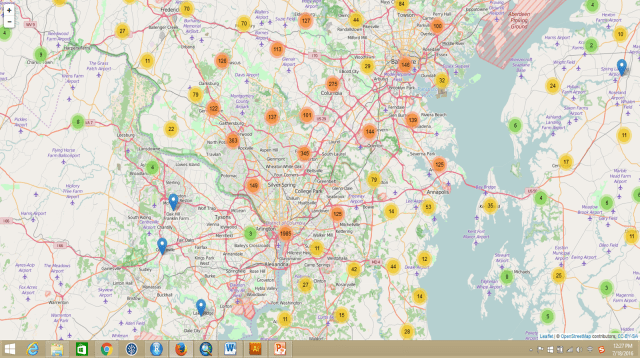
Another good location would be The District of Columbia (Washington D.C.) area. The East Coast has less solar energy resource (kW/m2) compared to the West Coast, especially California. However, the solar panel installations of homeowners around DC area are very high too. From maps above, we know that because the cost of installation is much lower, and the payback period is much faster compared to other parts of the country. It would be fascinating to dig out more information/factors behind their installation motivation. We could zoom in too much more detailed locations for each installation on this interactive map.
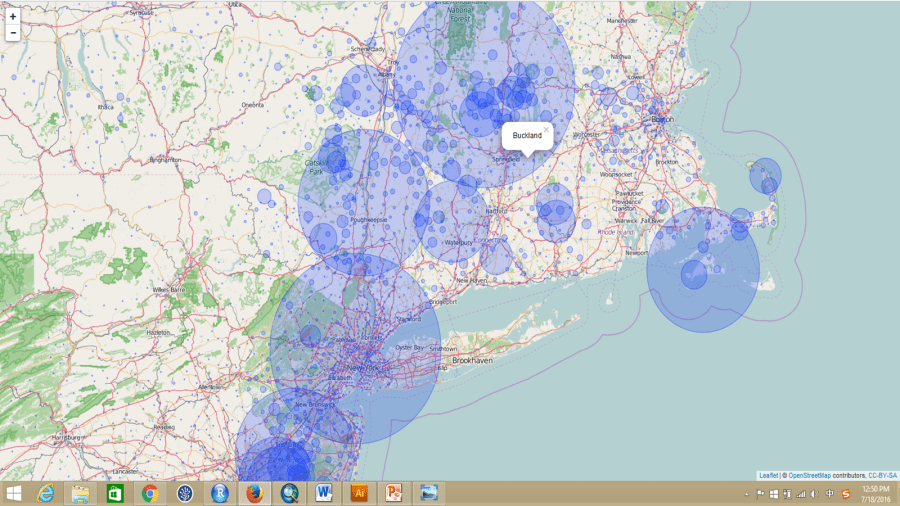
However, some areas, like DC and San Francisco, have a much larger population compared to other parts of US, which means there are going to be much more installations. An installation rate per 10,000 people would be much more appropriate. Therefore, I produced another interactive map with the installation rate per 10,000 people, the bigger the size of the circle is the higher rate of the installation.

The largest installation rate in the country is in the city of Ladera Ranch, located in South Orange County, California. Though, the reason behind it is not clear and more analysis is needed.

Buckland, MA has the highest installation on the East Coast. I can’t explain what the motivation behind it yet either. Further analysis of the household characteristics would be helpful. These two interactive maps were uploaded tomy GitHub repository, where you will be able to see the R code I wrote to process the data as well.
Public Data Sources
To answer these two questions, datasets of 1670M (1.67G) were downloaded and scraped from multiple sources:
(1). Electricity rate by zip codes;
(2). A 10km resolution of solar energy resources map, in ESRI shapefile, was downloaded the National Renewable Energy Laboratory (NREL); It was later extracted by zipcode polygon downloaded from ESRI ArcGIS online.
(3). Current solar panel installation data was scraped from the website of open PV website, a collection of installations by zip code. It requires registration to be able to access the data. It is part of NREL. The dataset includes the zip code of the installation, the cost, the size of the installation and the state of each location.
(4). Household income, education, the population of each zip code was obtained from US census.
(5). The average cost of the solar installation for each state was scraped from the website: Current cost of solar panels and Why Solar Energy? More of datasets for this proposal will be downloaded from the Department of Energy on GitHub via API.
Note: I cannot guarantee the accuracy of the analysis. My results are based on two days of data mining, wrangling, and analysis. The quality of the analysis is highly depended on the quality of the data and on how I understood the datasets in such limited time. A further validation of the analysis and datasets is needed.
For further contact the author, please find me on https://geoyi.org; or email me:geospatialanalystyi@gmail.com.